



Self-supervised learning is a type of machine learning where the model trains itself on large amounts of unlabeled data to extract features and useful representations without human intervention.
How does it work?
In self-supervised learning, the model takes in unlabeled data and tries to predict or reconstruct missing parts of the dataset or reconstruct parts transformed as a pretext task.
It uses internal representations to predict or reconstruct missing or transformed parts. For example, with a text-based task, the model is trained to predict missing words or the next sentence in a paragraph.
The learned representations after training can be used for downstream tasks, including image classification and language modeling. Since the model has learned to predict or reconstruct missing or transformed data, it can now capture important patterns in the input data.
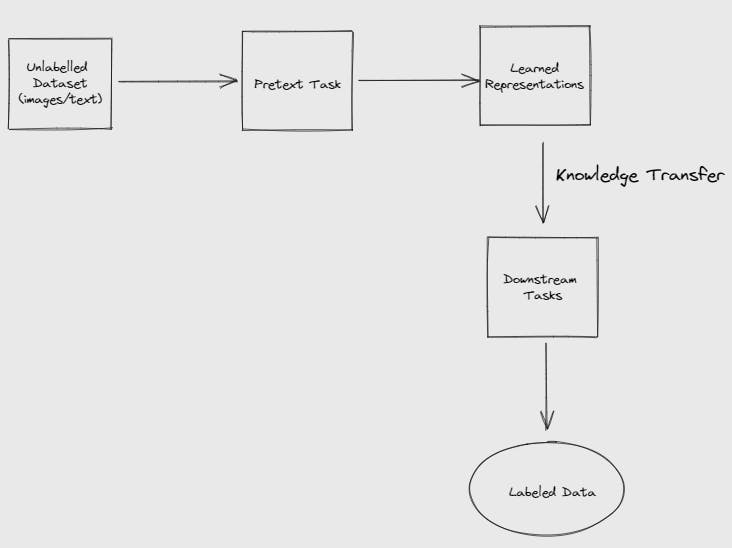
Here's another representation of a self-supervised learning model for computer vision applications:

Real-world applications of self-supervised learning
BERT (Bidirectional Encoder Representations from Transformers)
Hate-speech detection at Meta
XLM-R (Cross-lingual Language Model - RoBERTa)
Google's Medical Imaging Analysis Model
ChatGPT (unsupervised pre-training)
Comparison with other types of learning
The table below compares self-supervised, supervised, unsupervised, and semi-supervised learning.
Note: Please scroll horizontally to view the complete contents of the table.
Self-Supervised vs. Supervised vs. Unsupervised vs. Semi-Supervised Learning
Self-supervised learning | Supervised learning | Unsupervised learning | Semi-supervised learning | |
Description | Machine learning model trained with unlabeled data to create its own labels | Machine learning model trained on labeled data with known outputs | Machine learning model trained on unlabeled data with unknown outputs to identify patterns | Machine learning model trained with unlabeled data and some labeled data with a predefined learning objective |
Input Data | Training data used is unlabeled | Training data used is labeled | Training data used is unlabeled | Training data uses lots of unlabeled data and a small mix of labeled data |
When to use it | Used for predicting missing pieces of input data | Used to map inputs to outputs | Useful for findng patterns or structures in data | Used to improve accuracy with limited labeled data |
Model Building | Used for neural networks, autoencoders, contrastive learning, etc | Used in neural networks, decision trees, random forest models, etc | Used in anomaly detection, data compression, recommender systems, etc | Used in text classifiers, sentiment analysis, etc |
Applications | Image and video recognitionNatural Language ProcessingRobotics, etc | Speech recognitionFraud detectionObject detection | Anomaly detectionData compressionRecommender systems | Text classifierSentiment analysis |
Algorithms Used | Contrastive Predictive Coding (CPC)SimCLR MoCo | Support Vector Machines (SVMs)Naive Bayes | K-Means ClusteringPCA (Principal Component Analysis)t-SNE (t-distributed Stochastic Neighborhood Embedding) | Expectation-Maximization (EM) AlgorithmLabel Propagation |
Originally written for Educative Answers.