


Data profiling is a very vital step in the data cycle. It enables you to know the sort of data you’re working with and how to go about making use of it in the next stages, be it in analytics or machine learning. If you’re aiming at getting good results in your project, it is a very significant step, and through this, you can be able to tell your data has the right data quality metrics. These could be accuracy, completeness, timeliness, validity or consistency.
Kirk Borne refers to data profiling as taking your data on a “first date”. By this, we mean knowing what you’re dealing with up close, informing your decisions going forward and knowing the right steps to take to ensure you maximise the outcome of your project. The insights you can derive from the first date could point out errors in the dataset, outliers or missing values within the dataset or if the dataset comes in an inconsistent format.
What is Data Profiling?
Data profiling is a process of inspecting, evaluating and analysing the quality of data to have a better understanding of what it contains, its structure and how it can be used effectively.
Gartner defines it as a technology for discovering and investigating data quality issues, such as duplication, lack of consistency, and lack of accuracy and completeness.
Data Profiling vs Data Mining
The factors that differentiate data profiling and data mining aren’t very distinct, but MIT suggests two criteria for this, namely, distinction by the object of analysis and by the goal of the task.
For the first criterion, data profiling is focused on the analysis of the individual components of the dataset, while data mining tends to look at the dataset holistically, seeking patterns in large datasets.
The second criterion, regarding the goals of the task, data profiling is more focused on the description and summarization of existing data, while data mining goes beyond the data itself, aimed at generating insights.
In essence, data profiling focuses more on data evaluation and description, making sure there are no errors, inconsistencies or inaccurate values and summarising this in such a way useful details can be learned about the data. On the other hand, data mining is more insight-driven through the processes of data gathering, learning more about the data, and seeking patterns and insights that can, for example, influence businesses to make decisions backed by data.
Data Profiling vs Data Cleansing
These two are key components of the data cycle. Having quality data is an important step in any data project and should be a part of your everyday processes. As source data can be messy, it is essential that data profiling and data cleansing are not skipped as they usually go together.
We can say data profiling seeks to find irregularities in our dataset, while data cleansing is a multi-stage process after data profiling to fix these irregularities. Some of the processes in data cleansing include appending missing values, removing duplicates, filtering unwanted outliers, etc. While some of the processes in data profiling include analyzing large data quantities to ascertain their uniqueness and making sure fields are complete and there are no null values or anomalies.
For example, data profiling can help you reveal invalid entries, unnecessary whitespaces, invalid values etc., so you can easily fix the cause of the problem. Data cleansing, on the other hand, is the process that helps you standardise your data by, for example, taking out whitespaces, removing invalid entries or changing country abbreviations to full names.
Data Profiling: Use Cases
Several benefits come with data profiling, and as such, we will be discussing them under the following use cases:
Query optimization
Data cleansing
Data integration
Scientific data management
Data Analytics
Query Optimization
Data profiling for SQL databases involves explaining queries and is useful for evaluating the statistics of a database, improving the performance of slow queries and evaluating queries that appear to be returning anomalous data and providing the reason for what may be causing these results.
This further enhances the performance of relational databases, improves the execution of SQL statements and aids the estimation of the cost of a query plan.
Data Cleansing
Data profiling and cleansing usually go hand in hand as data cleansing usually follows after the profiling process. Profiling points out errors and inconsistencies in data, and cleansing helps fix and remove these errors.
Essentially, results inform decisions for data cleansing. For example, data profiling identifies corrupt or inaccurate records, while data cleansing seeks how to rectify these issues.
Data Integration
In a case where a dataset needs to be combined with another, and the components are unfamiliar to the integration expert, it’s necessary to carry out data profiling to understand the nature of the dataset, the size, data types, etc.
Data profiling, in this sense, involves running a column analysis and key and cross-domain analysis in order to have a better understanding of the nature and structure of the data you’re working with.
Scientific Data Management
Data profiling is very useful when working with the raw data gathered from scientific experiments. Data extracted online and transferred into a database or directly from scientific experiments have to be profiled for a proper structure to be created.
Data Analytics
For analytics to be carried out, profiling is an important step that enables the data analyst better understand the type of data they’re working on, what kind of tools to use and the sort of results to expect. As we discussed earlier, data profiling proceeds with data cleansing, which is an important step in data analytics.
Data Profiling Example
There are several examples we can discuss as regards data profiling, such as, picking out inconsistencies, viewing summary statistics or spotting patterns in a company’s database, healthcare records, bank records, sales and marketing data, etc.
Here we will be discussing data profiling for healthcare data, specifically Electronic Health Records (EHRs). For this type of dataset, data profiling can be used to spot duplicates and null values or identify columns that may require data cleaning and standardization.
Data profiling can come in handy when dealing with interoperable EHRs, which allow for health information exchanges, that is, data about a patient to be easily shared with healthcare providers across different healthcare facilities.
Another example could be the acquisition of one healthcare organisation by another, and profiling data would be necessary before migrating and integrating health records from both sides.
It is easier to make informed decisions about a patient’s treatment when there is sufficient data; this is why profiling is key when checking errors and seeking missing data or outliers in EHR.
How to do Data Profiling?
Steps to take when carrying out data profiling may depend on factors such as the number of sources, single or multiple, the number of columns, data overlap, etc. Data profiling that involves large amounts of data and goes beyond exploring SQL queries or spreadsheets has dedicated tools for this purpose.
Some data profiling tools are IBM InfoSphere Information Analyser, Informatica Data Explorer, Oracle Enterprise Data Quality, SAS DataFlux, MicroMelissa Data Profiler, Microsoft’s SQL Server Integration Services, etc.
And some open-source data profiling tools include Quadient DataCleaner, Aggregate Profiler, Talend Open Studio, OpenRefine, Apache Griffin etc.
Let’s discuss some tasks involved in data profiling.
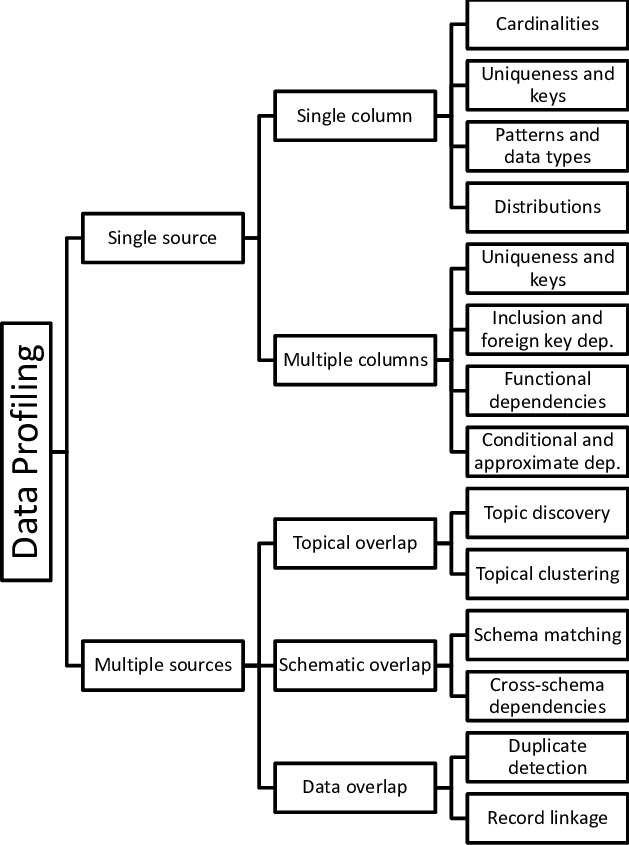
Traditional profiling addresses data profiling in its basic form, that is, working with databases which contain homogenous data in a single column. More advanced tasks and tools work with multiple, heterogeneous datasets. We will be discussing some of these tasks, including:
Cardinality
Uniqueness and key integrity
Patterns and data types
Distributions
Duplicate detection
Schema matching
Looking out for patterns and data types:
Cardinality: In data profiling, we take a holistic view of the dataset and analyze distinct values in our dataset. Also, this looks for relationships such as one-to-one, one-to-many, many-to-many, etc., in related datasets.
Uniqueness and Key Integrity: Uniqueness profiling helps when identifying duplicate data in rows and columns. A little similar to cardinality, which checks for the number of distinct values in our columns, uniqueness checks that each row in a table has unique values for each set of attributes. A high uniqueness score indicates there are no duplicates or overlaps.
Key integrity ensures they are no orphan keys. It also checks there is no zero, blank or null data present as missing or unknown data can cause issues.
Patterns and data types: Looking for patterns is a good way of checking if data is presented in the right format, such as emails and addresses. Also, having a look at the data types, which are typically strings, numeric values or dates, is an important part of data profiling.
Distributions: Frequency distributions are useful for authenticating a data source before designing a database. It reveals insightful characteristics and enables analyses such as range analysis, sparseness, value distribution, value absence, minimum value, maximum value, mean, median, standard deviation, etc.
Duplicate detection: While working with data integration using different sources, it is important to take into consideration duplicate detection as it is useful for identifying multiple records in a dataset that could be merged as one.
Schema matching: When integrating datasets, it is important to match the schemas of the datasets to ensure there are no existing duplicates.
Data Profiling: When Should It Happen?
Ralph Kimball, a popular author on data warehousing and business intelligence, suggests that data profiling is expected to come at the very beginning of every data project. This is because data that isn’t set in the right format or integrated properly can cause delays or errors when integrated with the database.
That said, data profiling carried out at the start of your project brings with it the following benefits:
Determines if a project is worth working on or not or if the dataset being used contains the right content for a project which can save a lot of time and resources.
It helps reveal hidden insights buried within the data you’re working with.
Issues with data quality can easily be handled with data profiling, as you verify the data in your tables and observe patterns and relationships. Understanding these issues determines the next procedures, such as data cleansing.
Data profiling also ensures that the data is standardised as well as improves the searchability of datasets.
Data profiling validates the accuracy of datasets, in addition to them being standardised and presented in a regular format, making them well suited for machine learning or further analysis.
The results from data profiling can be useful for measuring and monitoring the overall quality of a dataset. The insights gained from this are essential in revealing missing data, errors, outliers, inconsistent formatting, etc.
Conclusion
Data profiling is a crucial part of every data project, ensuring consistency and accuracy. It helps engineers draw useful conclusions as they are confident in the data as it has been validated and informs the need for data cleansing.
It also helps businesses make data-driven decisions as profiling offers insights and is useful for further analysis.
Data profiling offers several benefits, and with the present large amounts of data available, there are commercial and open-source profiling tools available to help with this.